Самообучение искусственного интеллекта: как технология RLAIF меняет согласованность моделей
2024/7/25 14:25:14
Вид:
В последнее время достижения и внимание к магистру права (LLM) резко возросли. С наступлением "лета" искусственного интеллекта методы обучения моделей также возрождаются с целью как можно быстрее получить оптимальные и высокопроизводительные модели. Хотя большинство из них достигается за счет крупномасштабных внедрений - больше микросхем, больше данных, больше этапов обучения, - многие команды сосредоточены на том, как более эффективно и умно тренировать эти модели, чтобы достичь желаемых результатов.
Обучение LLM обычно включает следующие этапы:
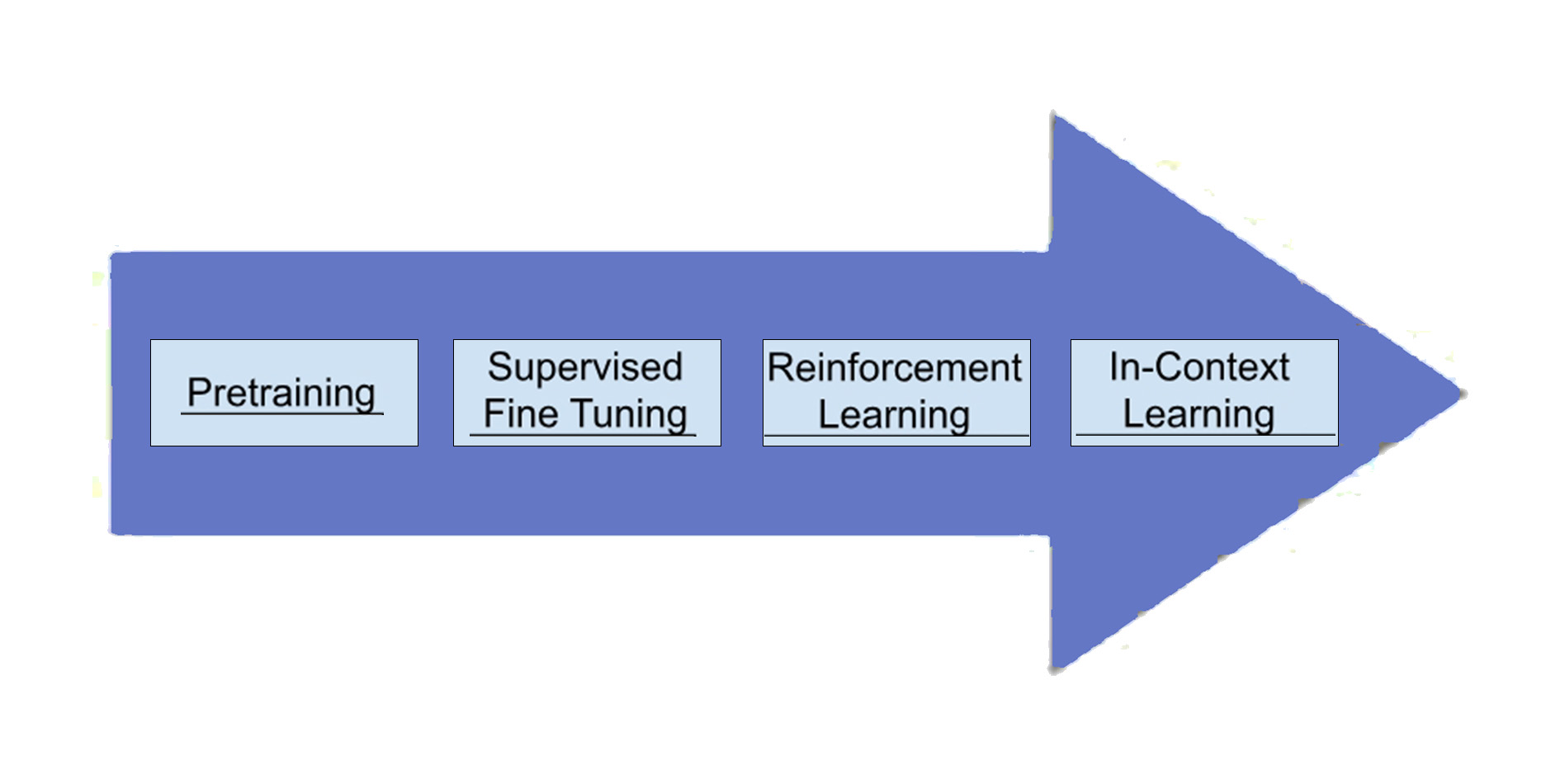
1. Предварительное обучение: На этом начальном этапе модель преобразуется из набора инертных нейронов в базовый генератор языка. Модель поглощает большое количество данных (например, весь интернет), но выходные данные обычно бессмысленны.
2. Контролируемая тонкая настройка (SFT): На этом этапе улучшаются возможности генерации модели, делая её выводы более последовательными и полезными. SFT учит модель создавать полезный, рациональный и связный контент, предоставляя конкретные примеры. После завершения этого этапа модель может быть развернута для производства.
3. Обучение с подкреплением (RL): На этом этапе, используя помеченные данные о предпочтениях, модель улучшает способность выходить за рамки явных инструкций, позволяя ей учиться на скрытых предпочтениях и желаниях пользователей.
4. Контекстное обучение: Также известная как инжиниринг подсказок, эта техника позволяет пользователям напрямую влиять на поведение модели во время вывода. Пользователи могут настраивать выходные данные модели в соответствии с конкретными потребностями и контекстами, используя такие методы, как ограничения и многократное обучение.
Кроме того, существуют и другие методы и этапы, которые можно включить в специальные процессы обучения.
Введение награды и обучения с подкреплением
Люди хорошо распознают шаблоны и обычно могут учиться и адаптироваться без сознательных усилий. Наше интеллектуальное развитие можно рассматривать как процесс непрерывного увеличения сложности распознавания шаблонов. Дети учатся не прыгать в лужи после того, как сталкиваются с негативными последствиями, подобно тому, как LLM проходят через SFT. Аналогично, подростки, наблюдающие за социальными взаимодействиями, учатся корректировать свое поведение на основе положительной и отрицательной обратной связи - суть обучения с подкреплением.
Ключевые компоненты практики обучения с подкреплением:
1. Данные о предпочтениях: Обучение с подкреплением в LLM обычно требует нескольких примеров выходных данных и одного запроса/входных данных, чтобы показать "градиенты". Например, в RLHF пользователям могут быть предоставлены запрос и два примера, и их просят выбрать, какой из них они предпочитают, или они могут получить выходные данные и попросить их улучшить, причём улучшенная версия считается "предпочтительным" вариантом.
2. Модель награды: Модель награды напрямую обучается на данных о предпочтениях, причём каждой реакции присваивается скалярное значение, указывающее её "ранг" в наборе. Модель награды затем обучается предсказывать эти скалярные значения для новых пар ввода-вывода.
3. Генеративная модель: Это окончательный ожидаемый результат. Во время обучения с подкреплением генеративная модель генерирует выходные данные, которые затем оцениваются моделью награды, и награда передается обратно алгоритму, чтобы определить, как изменить генеративную модель. Например, при положительной награде алгоритм обновляет модель, чтобы увеличить вероятность генерации данного выходного результата; при отрицательной награде он действует наоборот.
В области LLM RLHF была доминирующей силой. Сбор большого количества данных о предпочтениях людей значительно улучшил производительность LLM. Однако этот метод является дорогостоящим, трудоёмким и подвержен предвзятостям и уязвимостям.
Понимание RLAIF: Обзор использования AI-обратной связи для масштабирования выравнивания LLM
Основная идея RLAIF заключается в следующем: если LLM могут генерировать креативные текстовые форматы, такие как стихи, сценарии или даже код, почему они не могут учиться самостоятельно? Эта концепция самосовершенствования обещает достичь беспрецедентного уровня качества и эффективности, превосходя ограничения RLHF. Именно этого достигли исследователи с помощью RLAIF.
Инновация RLAIF заключается в его способности автоматически генерировать метки предпочтений в большом масштабе без необходимости в человеческом вводе. Хотя все LLM в конечном итоге происходят из данных, созданных человеком, RLAIF использует существующие LLM в качестве "учителей", чтобы направлять процесс обучения.
Методы RLAIF:
1. Контекстное обучение и инжиниринг подсказок: С помощью контекстного обучения и тщательно разработанных подсказок извлекается информация о предпочтениях от учителя LLM. Эти подсказки предоставляют контекст, примеры и образцы для оценки.
2. Аргументация цепочки мыслей: Подсказки цепочки мыслей (CoT) используются для улучшения способности учителя LLM к аргументации, что позволяет учителю делать более детализированные суждения о предпочтениях.
3. Решение проблемы смещения позиций: Чтобы уменьшить влияние порядка ответов на предпочтения учителя, RLAIF усредняет предпочтения, полученные из нескольких подсказок с разным порядком ответов.
Представьте себе уже хорошо обученный AI в качестве учителя. Учитель тестирует ученика, награждая за определенные действия и ответы. Ученик непрерывно улучшает своё поведение через обучение с подкреплением в этих тестах.
Преимущества RLAIF:
1. Оценка синтетических данных о предпочтениях: RLAIF использует "самонаграждаемые" баллы для сравнения вероятностей генерации двух ответов при контрастирующих подсказках, что отражает степень выравнивания каждого ответа.
2. Прямая оптимизация предпочтений (DPO): Использование самонаграждаемых баллов для оптимизации модели ученика, поощряя генерацию ответов, соответствующих человеческим ценностям.
Практические применения и преимущества RLAIF
Многофункциональность RLAIF распространяется на задачи, такие как суммаризация, генерация диалогов и генерация кода. Исследования показывают, что RLAIF может достичь сопоставимой или даже лучшей производительности по сравнению с RLHF, при этом снижая зависимость от человеческих аннотаций.
Кроме того, RLAIF открывает дверь к будущим "замкнутым" улучшениям магистра права. Модели учеников становятся более согласованными благодаря RLAIF и, в свою очередь, служат более надежными учительскими моделями для последующих итераций RLAIF, формируя положительную обратную связь без дополнительного человеческого вмешательства.
Как использовать RLAIF?
Если у вас уже есть RL-пайплайн, использование RLAIF относительно просто:
1. Начните с набора подсказок, разработанных для вызова желаемого поведения.
2. Создайте две слегка разные версии каждой подсказки, подчеркивая различные аспекты целевого поведения.
3. Зафиксируйте ответы ученика LLM на каждую вариацию подсказки.
4. Создайте метаподсказки, чтобы получить информацию о предпочтениях от учителя LLM для каждой пары подсказка-ответ.
5. Используйте данные о предпочтениях, сгенерированные в существующем RL-пайплайне, чтобы направлять обучение и оптимизацию модели ученика.
Проблемы и ограничения
Несмотря на свой потенциал, RLAIF сталкивается с проблемами. Точность аннотаций AI остаётся проблемой, так как предвзятости в учителе LLM могут передаваться на модель ученика. Кроме того, исследования показывают, что модели, согласованные с RLAIF, иногда генерируют фактически несоответствующие или менее последовательные ответы, что требует дальнейшего изучения методов улучшения качества генерируемого текста.
Возникающие тренды и будущие исследования
Появление RLAIF вызвало захватывающие направления исследований, такие как изучение тонко настроенных механизмов обратной связи, интеграция мультимодальной информации, применение принципов учебных курсов в RLAIF и изучение потенциала положительных обратных связей в RLAIF, а также интеграция обратной связи из реального мира для повышения качества.
Вывод: RLAIF как трамплин к согласованному развитию AI
RLAIF предлагает мощный и эффективный метод выравнивания LLM, предоставляя значительные преимущества по сравнению с традиционными методами RLHF. Его масштабируемость, экономическая эффективность и потенциал к самосовершенствованию внушают большие надежды на будущее развития AI. Признавая текущие проблемы и ограничения, продолжающиеся исследования активно прокладывают путь к более надежным, объективным и этичным рамкам RLAIF. Продолжая исследовать эту захватывающую границу, RLAIF станет трамплином к будущему, в котором LLM будут бесшовно интегрироваться с человеческими ценностями и ожиданиями, полностью раскрывая потенциал искусственного интеллекта на благо общества.





